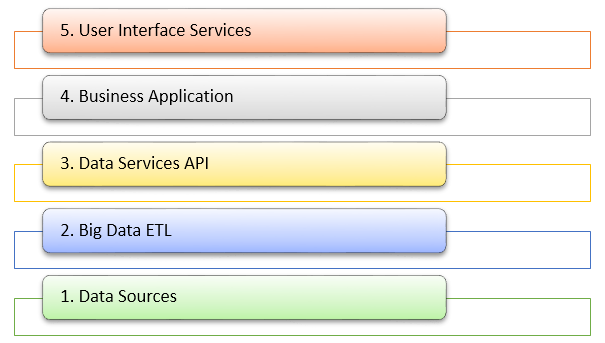
If your company is still managing its data using mainframe, then there may be a little yellow elephant in the room. As organizations look more and more to Big Data to help them garner the necessary business intelligence required to make informed decisions, the growing need for Big Data processing is becoming increasingly unavoidable.
True, it’s very easy to forget that in this smartphone, Facebook and Twitter dominated world that the data stored on your mainframe – transactional data, for instance, bookings, feedback etc. ¬– is actually of as much importance now and to Big Data as it has ever been. Mainframes simply just don’t enter the technology conversations very much anymore – but they are, of course, critical.
Mainframes Generate Data
Much of the world’s largest and most critical industries – healthcare, finance, insurance, retail etc. – still generate a huge majority of their data from mainframe. Put simply, mainframe data cannot be ignored, but the time has come to start offloading that data onto a Big Data analytics platform.Indeed, if you haven’t done so already, then it’s seemingly inevitable that you will one day find yourself – just like numerous other mainframe professionals – beginning the process of offloading your mainframe batch to a framework like Hadoop.
You will, no doubt, already be aware of this pressing, modern day desideratum – but are you ready to make such a seismic shift? Do you have a big data strategy in place, and what skills will you need? But perhaps the first question you should be asking yourself is – is it the right decision?
Without meaning to seem curt – yes, it is, quite frankly, and here’s why:
The Advantages of Moving From Mainframe to Hadoop:
- Mainframe is helplessly quarantined in the world of structured data (sales data, purchase orders, customer location etc.), from which analysts can only glean so much. Hadoop, on the other hand, handles and processes a much higher volume and variety of unstructured Big Data (documents, texts, images, social media, mobile data etc.) that’s generated by business, providing analysts with a much more detailed information cache to work with.
- Licensing fees for mainframe software – as well as mainframe maintenance and support costs – are minimized when migrating to a Hadoop solution.
- Eradicates the need to purchase more mainframes as processing demands increase in line with business growth.
- Mainframe coding is outdated and inefficient.
- Hadoop is open-source, rendering it cost effective in the first instance, but the time that it saves in batch processing data is an economic no-brainer in itself.
- The technology already underpins gigantic technology firms such as Google, Yahoo, Facebook, Twitter, eBay and many more, proving its worth.
- We live in the age of Big Data, and it’s growing exponentially with each second that ticks by. Utilizing this data is the only way that you can help your company stay competitive in the global business world – after all, everyone else is using it.
- If you’ve mastered mainframe, you’ll be more than capable of learning Hadoop, which is much simpler in spite of its superior power as a processor.
So, what are the Challenges of Moving from Mainframe to Big Data and Hadoop?
Integration
There’s a common misconception that moving mainframe data to Hadoop is simple. It’s not. For the most part this is because you’ll require the need of two teams, or at least two people – one who understands mainframe, the other who understands Hadoop. Finding someone who’s skilled in both is very difficult indeed (see ‘Professional Skills and Skilled Professionals’ below).
In the first instance, your mainframe professional will have to identify and select the data required for transfer – something that Hadoop developers will find difficult if not impossible to do themselves. The data then needs to be prepared –customer data may need to be filtered or aggregated for example – before it can then be translated into a language that is understood by Hadoop.
But, even after all this, the mainframe data still has to be rationalized with the COBOL copybook – something that requires a very particular skillset, and one that the Hadoop professional will almost certainly not have. But, once this stage is complete, you can finally make the FTP transfer and load up the files to Hadoop. Obviously the transition is achievable, but you have to be prepared for this very techy adventure along the way.
Security
The highly sensitive data contained in your mainframe means that all transfers onto Hadoop must be made with utmost care. Not a single mistake can be made when transferring data, and security must be guaranteed across the whole process.
The huge security challenge that this presents can often mean that extraction software has to be installed in the first instance onto the mainframe. If you find this to be the case, then it’s absolutely imperative that you ensure that anything you install onto the mainframe to bring data into Hadoop is proven enterprise-grade software that can boast a watertight security track record and reputation. Using an authorization protocol for all users is an absolute must.
Cost
One of the main attractions of a Hadoop migration from mainframe is that organizations are looking to reduce IT expenses by curbing the amount of data that is being processed on their mainframe. The cost of storage can be hugely reduced on Hadoop clusters as compared to their mainframe counterparts. The cost of managing a single terabyte of data in a mainframe environment can be anything from $20,000 to $100,000, whereas on Hadoop this is reduced to about $1,000 (SearchDataManagement).
It is no surprise, then, that in the most part mainframe modernization efforts have stalled. They are very risky initiatives as well as being expensive, and Hadoop is plugging the gap.
Professional Skills and Skilled Professionals
The future is almost certainly set for Hadoop to overtake mainframe as the default data managing system. As a result, this growing interest in Hadoop technologies is driving a huge demand for data scientists with Big Data skills. Companies will always need to find ways of staying competitive in the world of global business, and the intelligent utilization of big data is absolutely imperative in achieving this.
However, the charge of analyzing, classifying and drawing pertinent information from the enormous hordes of unstructured raw data requires the services of highly skilled and trained data professionals, and, quite simply, there’s currently a shortage of such people.
The USA alone faces a shortage of between 140,000 and 190,000 big data professionals with the analytical skills required to make key business decisions based on Big Data analysis.
However, what this does indicate is big career opportunities for mainframe professionals. Companies that are transitioning to Hadoop want people with experience and knowledge of analytics, and so, if you’re a mainframe professional, then the time is now to start bolstering your skills set and start learning Hadoop and its approaches (MapReduce and the like).
Storage
Big Data, by its very nature, is growing so fast that it is becoming nigh on impossible to keep up with. Indeed, there isn’t even the storage space to cope with it all. As early as 2010, there was already 35% more digital information created than the capacity exists to store it, with the figure approaching 60% today. Indeed, writing in Forbes Christopher Frank points out that 90% of the data in the world today has been crated in the last two years alone.
IBM Plug Skills Gap
Clearly, the Big Data skills gap needs to be plugged, and is something that has garnered global attention. Indeed, IBM has made a significant move towards solving the problem. Partnering with more than 1000 universities worldwide, IBM last year announced nine new academic collaborations designed to prepare students for the 4.4 million jobs that are set to be created globally to support Big Data by 2015.
The hope – and the need – is to create a massive new fleet of knowledgeable professionals who can use ‘out of the box’ thinking to draw relevant inferences from the wealth of Big Data available to them, and convert the findings into meaningful business strategies. Eventually, nearly every area of research will be using Big Data analysis to draw conclusions that will affect how those specific businesses operate. And the pool is huge. Computing, humanities, social sciences, medicine, natural history – anything and everything will one day benefit from Big Data.
The point is that no matter what field you’re working in, despite the challenges of recruitment surrounding Big Data analytics, the opportunities that it represents mean that sooner or later your skills as solely a mainframe professional will not suffice. For companies, finding the right person for the Big Data job role is the biggest challenge. Your transition from mainframe to Hadoop might still be in process, and of course the move might not be entire – you may still have some very pertinent uses for your mainframe. Finding the right person with the right skills to match the present and future requirements of your data management is indeed the most pressing demand.