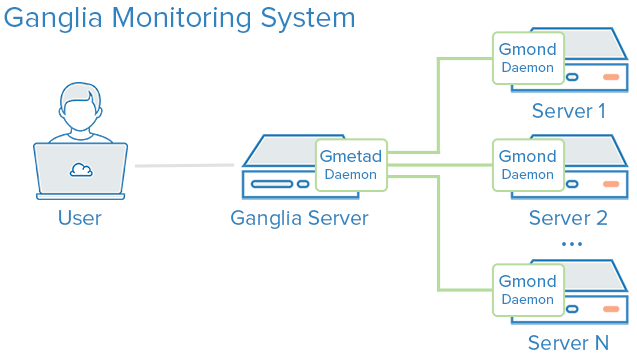
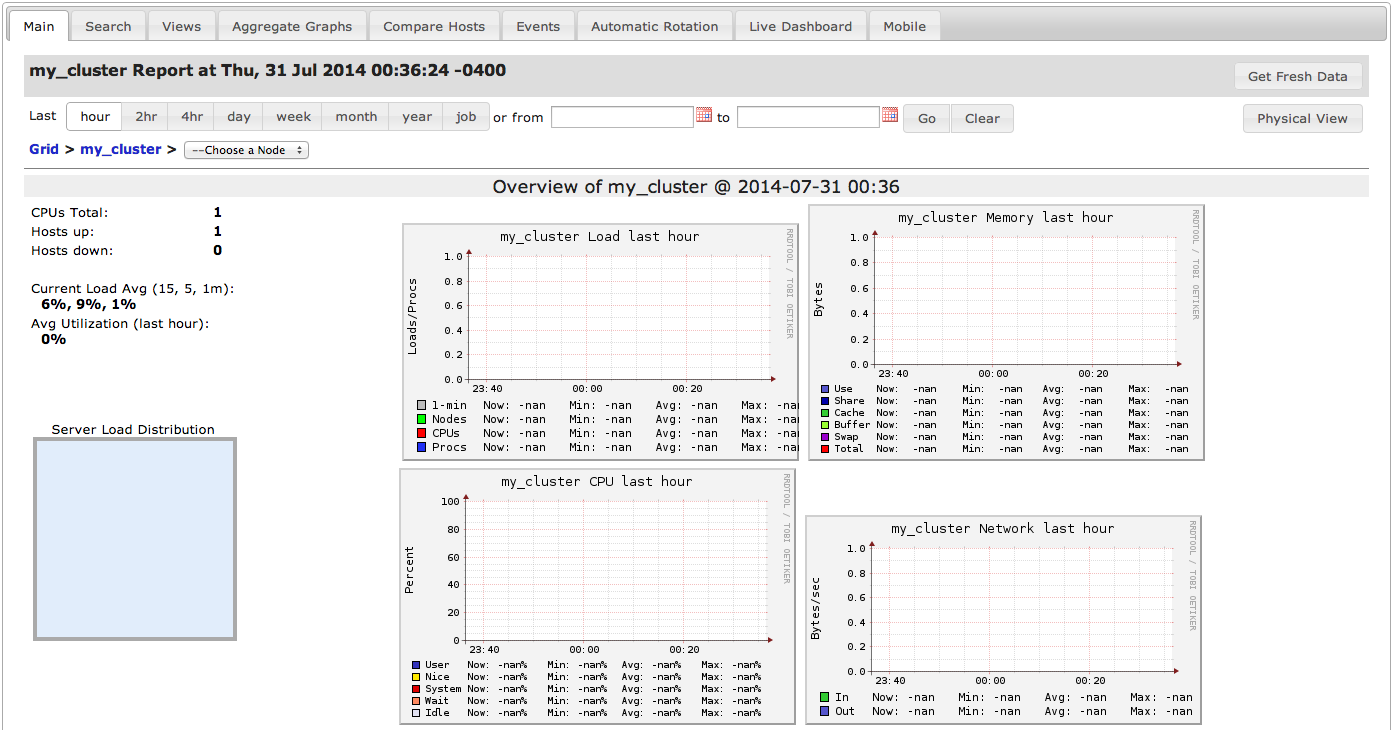
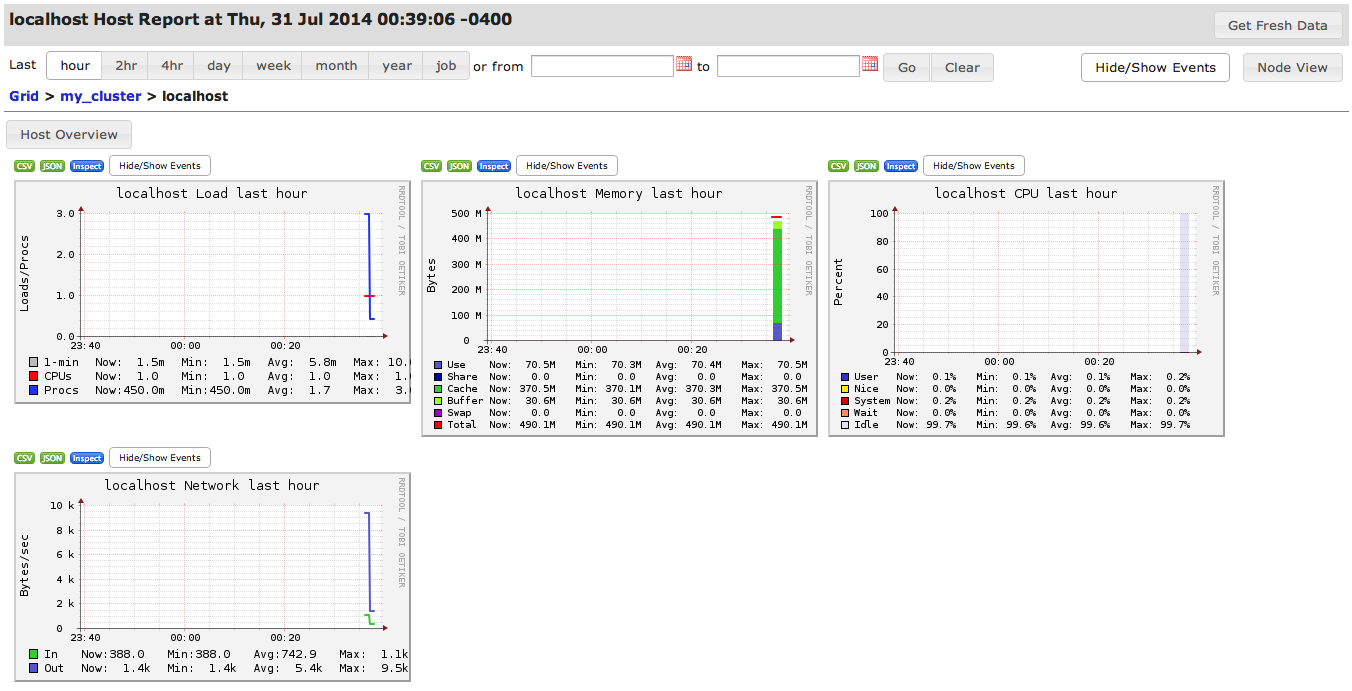
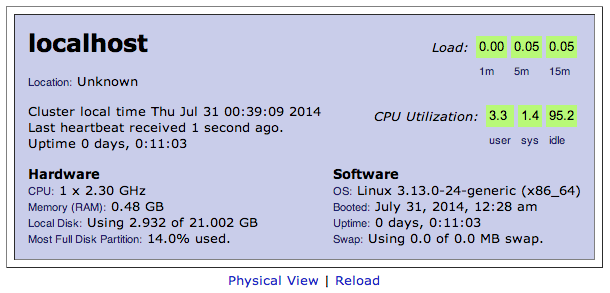
This post is about monitoring the Hadoop metrics such as HDFS, MAPREDUCE, JVM, RPC and UGI using the Ganglia Monitoring Tool.
I assume that the readers of blog have prior knowledge of Ganglia and Hadoop technology.
To integrate the Ganglia with Hadoop you need to configure hadoop-metrics.properties file of hadoop located inside the hadoop conf folder. In this configuration file you need to configure the server address of ganglia gmetad, period for sending metrics data and ganglia context class name.
The format and name of hadoop metrics properties file is different for various hadoop versions.
For Hadoop 0.20.x, 0.21.0 and 0.22.0 versions, the file name is hadoop-metrics.properties.
For Hadoop 1.x.x and 2.x.x versions, the file name is hadoop-metrics2.properties.
The ganglia context class name also differs with version change of ganglia, for detailed information about Ganglia Context class you can read from GangliaContext.
Procedure of configuring the hadoop metrics properties file: ---------------------------------------------------------------------------------------------
1. Configuration for 2.x.x versions: In such hadoop versions the metrics properties file is located inside the $HADOOP_HOME/etc/hadoop/ folder. Configure thehadoop-metrics2.properties file using the code as shown below:
namenode.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
namenode.sink.ganglia.period=10
namenode.sink.ganglia.servers=gmetad_server_ip:8649
datanode.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
datanode.sink.ganglia.period=10
datanode.sink.ganglia.servers=gmetad_server_ip:8649
resourcemanager.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
resourcemanager.sink.ganglia.period=10
resourcemanager.sink.ganglia.servers=gmetad_server_ip:8649
nodemanager.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
nodemanager.sink.ganglia.period=10
nodemanager.sink.ganglia.servers=gmetad_server_ip:8649
2. Configuration for 1.x.x versions: In such hadoop versions the metrics properties file is located inside the $HADOOP_HOME/conf/ folder. Configure the hadoop-metrics2.properties file using the code as shown below:
namenode.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
namenode.sink.ganglia.period=10
namenode.sink.ganglia.servers=gmetad_server_ip:8649
datanode.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
datanode.sink.ganglia.period=10
datanode.sink.ganglia.servers=gmetad_server_ip:8649
jobtracker.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
jobtracker.sink.ganglia.period=10
jobtracker.sink.ganglia.servers=gmetad_server_ip:8649
tasktracker.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
tasktracker.sink.ganglia.period=10
tasktracker.sink.ganglia.servers=gmetad_server_ip:8649
maptask.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
maptask.sink.ganglia.period=10
maptask.sink.ganglia.servers=gmetad_server_ip:8649
reducetask.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
reducetask.sink.ganglia.period=10
reducetask.sink.ganglia.servers=gmetad_server_ip:8649
3. Configuration for 0.20.x, 0.21.0 and 0.22.0 versions: In such hadoop versions the metrics properties file is located inside the $HADOOP_HOME/conf/ folder. Configure the hadoop-metrics.properties file using the code as shown below:
dfs.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
dfs.period=10
dfs.servers=gmetad_server_ip:8649
mapred.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
mapred.period=10
mapred.servers=gmetad_server_ip:8649
jvm.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
jvm.period=10
jvm.servers=gmetad_server_ip:8649
rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
rpc.period=10
rpc.servers=gmetad_server_ip:8649
ugi.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
ugi.period=10
ugi.servers=gmetad_server_ip:8649
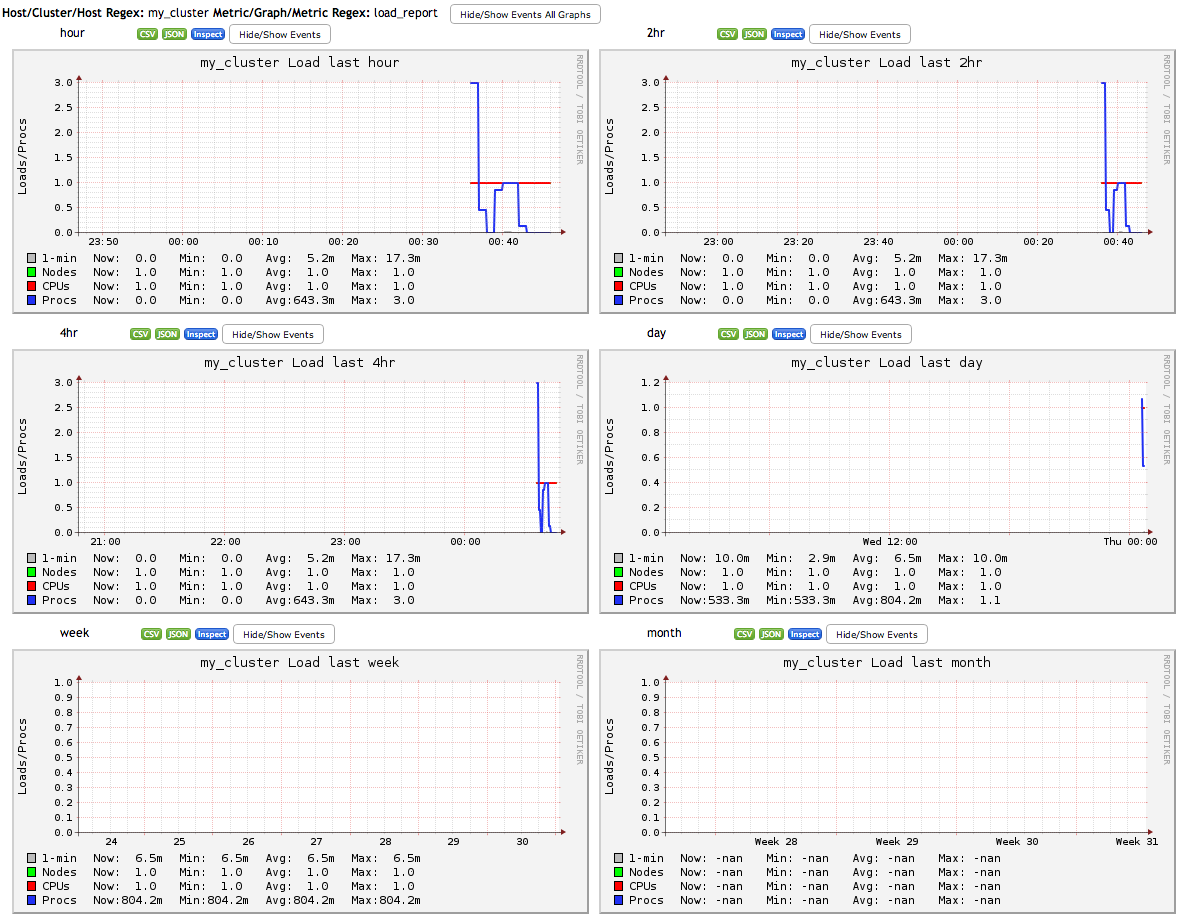
The above configuration is for the unicast mode of Ganglia. However, if you are running Ganglia in multicast mode then you need to use the multicast address in place of gmetad_server_ip in the configuration file. Once you have applied the above changes, then you need to restart the gmetad and gmond services of Ganglia on the nodes. You also need to restart Hadoop services if they are running. Once you are done with restarting the services, the Ganglia UI displays the Hadoop graphs. InitiallyGanglia UI does not show graphs for the jobs, they will appear on UI only after submitting a job in Hadoop.
I assume that the readers of blog have prior knowledge of Ganglia and Hadoop technology.
To integrate the Ganglia with Hadoop you need to configure hadoop-metrics.properties file of hadoop located inside the hadoop conf folder. In this configuration file you need to configure the server address of ganglia gmetad, period for sending metrics data and ganglia context class name.
The format and name of hadoop metrics properties file is different for various hadoop versions.
For Hadoop 0.20.x, 0.21.0 and 0.22.0 versions, the file name is hadoop-metrics.properties.
For Hadoop 1.x.x and 2.x.x versions, the file name is hadoop-metrics2.properties.
The ganglia context class name also differs with version change of ganglia, for detailed information about Ganglia Context class you can read from GangliaContext.
Procedure of configuring the hadoop metrics properties file: ---------------------------------------------------------------------------------------------
1. Configuration for 2.x.x versions: In such hadoop versions the metrics properties file is located inside the $HADOOP_HOME/etc/hadoop/ folder. Configure thehadoop-metrics2.properties file using the code as shown below:
namenode.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
namenode.sink.ganglia.period=10
namenode.sink.ganglia.servers=gmetad_server_ip:8649
datanode.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
datanode.sink.ganglia.period=10
datanode.sink.ganglia.servers=gmetad_server_ip:8649
resourcemanager.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
resourcemanager.sink.ganglia.period=10
resourcemanager.sink.ganglia.servers=gmetad_server_ip:8649
nodemanager.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
nodemanager.sink.ganglia.period=10
nodemanager.sink.ganglia.servers=gmetad_server_ip:8649
2. Configuration for 1.x.x versions: In such hadoop versions the metrics properties file is located inside the $HADOOP_HOME/conf/ folder. Configure the hadoop-metrics2.properties file using the code as shown below:
namenode.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
namenode.sink.ganglia.period=10
namenode.sink.ganglia.servers=gmetad_server_ip:8649
datanode.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
datanode.sink.ganglia.period=10
datanode.sink.ganglia.servers=gmetad_server_ip:8649
jobtracker.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
jobtracker.sink.ganglia.period=10
jobtracker.sink.ganglia.servers=gmetad_server_ip:8649
tasktracker.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
tasktracker.sink.ganglia.period=10
tasktracker.sink.ganglia.servers=gmetad_server_ip:8649
maptask.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
maptask.sink.ganglia.period=10
maptask.sink.ganglia.servers=gmetad_server_ip:8649
reducetask.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
reducetask.sink.ganglia.period=10
reducetask.sink.ganglia.servers=gmetad_server_ip:8649
3. Configuration for 0.20.x, 0.21.0 and 0.22.0 versions: In such hadoop versions the metrics properties file is located inside the $HADOOP_HOME/conf/ folder. Configure the hadoop-metrics.properties file using the code as shown below:
dfs.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
dfs.period=10
dfs.servers=gmetad_server_ip:8649
mapred.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
mapred.period=10
mapred.servers=gmetad_server_ip:8649
jvm.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
jvm.period=10
jvm.servers=gmetad_server_ip:8649
rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
rpc.period=10
rpc.servers=gmetad_server_ip:8649
ugi.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
ugi.period=10
ugi.servers=gmetad_server_ip:8649
The above configuration is for the unicast mode of Ganglia. However, if you are running Ganglia in multicast mode then you need to use the multicast address in place of gmetad_server_ip in the configuration file. Once you have applied the above changes, then you need to restart the gmetad and gmond services of Ganglia on the nodes. You also need to restart Hadoop services if they are running. Once you are done with restarting the services, the Ganglia UI displays the Hadoop graphs. InitiallyGanglia UI does not show graphs for the jobs, they will appear on UI only after submitting a job in Hadoop.