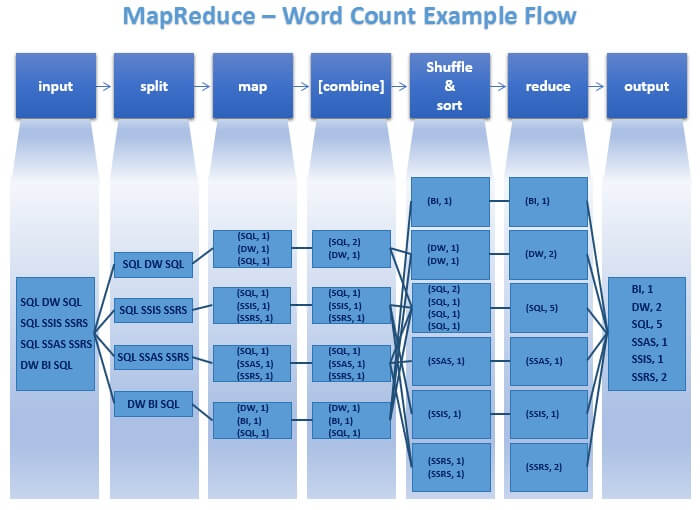
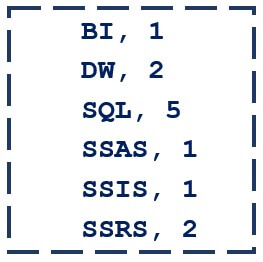
Since MapReduce and HDFS are complex distributed systems that run
arbitrary user code, there’s no hard and fast set of rules to achieve
optimal performance; instead, I tend to think of tuning a cluster or job
much like a doctor would treat a sick human being. There are a number
of key symptoms to look for, and each set of symptoms leads to a
different diagnosis and course of treatment.
In medicine, there’s no automatic process that can replace the
experience of a well seasoned doctor. The same is true with complex
distributed systems — experienced users and operators often develop a
“sixth sense” for common issues. Having worked with BigData customers
in a number of different industries, each with a different workload,
dataset, and cluster hardware, I’ve accumulated a bit of this
experience, and would like to share some with you today.
In this blog post, I’ll highlight a few tips for improving MapReduce
performance. The first few tips are cluster-wide, and will be useful for
operators and developers alike. The latter tips are for developers
writing custom MapReduce jobs in Java. For each tip, I’ll also note a
few of the “symptoms” or “diagnostic tests” that indicate a particular
remedy might bring you some good improvements.
Please note, also, that these tips contain lots of rules of thumb
based on my experience across a variety of situations. They may not
apply to your particular workload, dataset, or cluster, and you should
always benchmark your jobs before and after any changes. For these tips,
I’ll show some comparative numbers for a 40GB wordcount job on a small
4-node cluster. Tuned optimally, each of the map tasks in this job runs
in about 33 seconds, and the total job runtime is about 8m30s.
Tip 1) Configure your cluster correctly
Diagnostics/symptoms:
top shows slave nodes fairly idle even when all map and reduce task slots are filled up running jobs.top shows kernel processes like RAID (mdX_raid*) or pdflush taking most of the CPU time.- Linux load averages are often seen more than twice the number of CPUs on the system.
- Linux load averages stay less than half the number of CPUs on the system, even when running jobs.
- Any swap usage on nodes beyond a few MB.
The first step to optimizing your MapReduce performance is to make
sure your cluster configuration has been tuned. For starters, check out
our earlier
blog post on configuration parameters.
In addition to those knobs in the Hadoop configuration, here are a few
more checklist items you should go through before beginning to tune the
performance of an individual job:
- Make sure the mounts you’re using for DFS and MapReduce storage have been mounted with the
noatime option. This disables access time tracking and can improve IO performance.
- Avoid RAID and LVM on TaskTracker and DataNode machines – it generally reduces performance.
- Make sure you’ve configured
mapred.local.dir and dfs.data.dir to point to one directory on each of your disks to ensure that all of your IO capacity is used. Run iostat -dx 5 from the sysstat package while the cluster is loaded to make sure each disk shows utilization.
- Ensure that you have SMART
monitoring for the health status of your disk drives. MapReduce jobs
are fault tolerant, but dying disks can cause performance to degrade as
tasks must be re-executed. If you find that a particular TaskTracker
becomes blacklisted on many job invocations, it may have a failing
drive.
- Monitor and graph swap usage and network usage with software like Ganglia. Monitoring Hadoop metrics in Ganglia is also a good idea. If you see swap being used, reduce the amount of RAM allocated to each task in
mapred.child.java.opts.
Benchmarks:
Unfortunately I was not able to perform benchmarks for this tip, as
it would involve re-imaging the cluster. If you have had relevant
experience, feel free to leave a note in the Comments section below.
Tip 2) Use LZO Compression
Diagnostics/symptoms:
- This is almost always a good idea for intermediate data! In the doctor analogy, consider LZO compression your vitamins.
- Output data size of MapReduce job is nontrivial.
- Slave nodes show high
iowait utilization in top and iostat when jobs are running.
Almost every Hadoop job that generates an non-negligible amount of
map output will benefit from intermediate data compression with LZO.
Although LZO adds a little bit of CPU overhead, the reduced amount of
disk IO during the shuffle will usually save time overall.
Whenever a job needs to output a significant amount of data, LZO
compression can also increase performance on the output side. Since
writes are replicated 3x by default, each GB of output data you save
will save 3GB of disk writes.
In order to enable LZO compression, check out our
recent guest blog from Twitter. Be sure to set
mapred.compress.map.output to
true.
Benchmarks:
Disabling LZO compression on the wordcount example increased the job runtime only slightly on our cluster. The
FILE_BYTES_WRITTEN
counter increased from 3.5GB to 9.2GB, showing that the compression
yielded a 62% decrease in disk IO. Since this job was not sharing the
cluster, and each node has a high ratio of number of disks to number of
tasks, IO is not the bottleneck here, and thus the improvement was not
substantial. On clusters where disks are pegged due to a lot of
concurrent activity, a 60% reduction in IO can yield a substantial
improvement in job completion speed.
Tip 3) Tune the number of map and reduce tasks appropriately
Diagnostics/symptoms:
- Each map or reduce task finishes in less than 30-40 seconds.
- A large job does not utilize all available slots in the cluster.
- After most mappers or reducers are scheduled, one or two remains pending and then runs all alone.
Tuning the number of map and reduce tasks for a job is important and
easy to overlook. Here are some rules of thumb I use to set these
parameters:
- If each task takes less than 30-40 seconds, reduce the number of
tasks. The task setup and scheduling overhead is a few seconds, so if
tasks finish very quickly, you’re wasting time while not doing work. JVM
reuse can also be enabled to solve this problem.
- If a job has more than 1TB of input, consider increasing the block
size of the input dataset to 256M or even 512M so that the number of
tasks will be smaller. You can change the block size of existing files
with a command like
hadoop distcp -Ddfs.block.size=$[256*1024*1024] /path/to/inputdata /path/to/inputdata-with-largeblocks. After this command completes, you can remove the original data.
- So long as each task runs for at least 30-40 seconds, increase the
number of mapper tasks to some multiple of the number of mapper slots in
the cluster. If you have 100 map slots in your cluster, try to avoid
having a job with 101 mappers – the first 100 will finish at the same
time, and then the 101st will have to run alone before the reducers can
run. This is more important on small clusters and small jobs.
- Don’t schedule too many reduce tasks – for most jobs, we recommend a
number of reduce tasks equal to or a bit less than the number of reduce
slots in the cluster.
Benchmarks:
To make the wordcount job run with too many tasks, I ran it with the argument
-Dmapred.max.split.size=$[16*1024*1024].
This yielded 2640 tasks instead of the 360 that the framework chose by
default. When running with this setting, each task took about 9 seconds,
and watching the Cluster Summary view on the JobTracker showed the
number of running maps fluctuating between 0 and 24 continuously
throughout the job. The entire job finished in 17m52s, more than twice
as slow as the original job.
Tip 4) Write a Combiner
Diagnostics/symptoms:
- A job performs aggregation of some sort, and the Reduce input groups counter is significantly smaller than the Reduce input records counter.
- The job performs a large shuffle (e.g. map output bytes is multiple GB per node)
- The number of spilled records is many times larger than the number of map output records as seen in the Job counters.
If your algorithm involves computing aggregates of any sort, chances
are you can use a Combiner in order to perform some kind of initial
aggregation before the data hits the reducer. The MapReduce framework
runs combiners intelligently in order to reduce the amount of data that
has to be written to disk and transfered over the network in between the
Map and Reduce stages of computation.
Benchmarks:
I modified the word count example to remove the call to
setCombinerClass,
and otherwise left it the same. This changed the average map task run
time from 33s to 48s, and increased the amount of shuffled data from 1GB
to 1.4GB. The total job runtime increased from 8m30s to 15m42s, nearly a
factor of two. Note that this benchmark was run with map output
compression enabled – without map output compression, the effect of the
combiner would have been even more important.
Tip 5) Use the most appropriate and compact Writable type for your data
Symptoms/diagnostics:
Text objects are used for working with non-textual or complex dataIntWritable or LongWritable objects are used when most output values tend to be significantly smaller than the maximum value.
When users are new to programming in MapReduce, or are switching from Hadoop Streaming to Java MapReduce, they often use the
Text writable type unnecessarily. Although
Text
can be convenient, converting numeric data to and from UTF8 strings is
inefficient and can actually make up a significant portion of CPU time.
Whenever dealing with non-textual data, consider using the binary
Writables like
IntWritable,
FloatWritable, etc.
In addition to avoiding the text parsing overhead, the binary
Writable types will take up less space as intermediate data. Since disk
IO and network transfer will become a bottleneck in large jobs, reducing
the sheer number of bytes taken up by the intermediate data can provide
a substantial performance gain. When dealing with integers, it can also
sometimes be faster to use
VIntWritable or
VLongWritable
— these implement variable-length integer encoding which saves space
when serializing small integers. For example, the value 4 will be
serialized in a single byte, whereas the value 10000 will be serialized
in two. These variable length numbers can be very effective for data
like counts, where you expect that the majority of records will have a
small number that fits in one or two bytes.
If the Writable types that ship with Hadoop don’t fit the bill,
consider writing your own. It’s pretty simple, and will be significantly
faster than parsing text. If you do so, make sure to provide a
RawComparator — see the source code for the built in Writables for an example.
Along the same vein, if your MapReduce job is part of a multistage workflow, use a binary format like
SequenceFile
for the intermediate steps, even if the last stage needs to output
text. This will reduce the amount of data that needs to be materialized
along the way.
Benchmarks:
For the example word count job, I modified the intermediate count values to be
Text type rather than
IntWritable. In the reducer, I used
Integer.parseString(value.toString())
when accumulating the sum. The performance of the suboptimal version of
the WordCount was about 10% slower than the original. The full job ran
in a bit over 9 minutes, and each map task took 36 seconds instead of
the original 33. Since integer parsing is itself rather fast, this did
not represent a large improvement; in the general case, I have seen
using more efficient Writables to make as much as a 2-3x difference in
performance.
Tip 6) Reuse Writables
Symptoms/diagnostics:
- Add
-verbose:gc -XX:+PrintGCDetails to mapred.child.java.opts.
Then inspect the logs for some tasks. If garbage collection is frequent
and represents a lot of time, you may be allocating unnecessary
objects.
- grep for “
new Text” or “new IntWritable” in your code base. If you find this in an inner loop, or inside the map or reduce functions this tip may help.
- This tip is especially helpful when your tasks are constrained in RAM.
One of the first mistakes that many MapReduce users make is to allocate a new
Writable object for every output from a mapper or reducer. For example, one might implement a word-count mapper like this:
public void map(...) {
...
for (String word : words) {
output.collect(new Text(word), new IntWritable(1));
}
}
This implementation causes thousands of very short-lived objects to
be allocated. While the Java garbage collector does a reasonable job at
dealing with this, it is more efficient to write:
class MyMapper ... {
Text wordText = new Text();
IntWritable one = new IntWritable(1);
public void map(...) {
...
for (String word : words) {
wordText.set(word);
output.collect(word, one);
}
}
}
Benchmarks:
When I modified the word count example as described above, I
initially found it made no difference in the run time of the job. This
is because this cluster’s default settings include a 1GB heap size for
each task, so garbage collection never ran. However, running it with
each task allocated only 200mb of heap size showed a drastic slowdown in
the version that did not reuse Writables — the total job runtime
increased from around 8m30s to over 17 minutes. The original version,
which does reuse Writables, stayed the same speed even with the smaller
heap. Since reusing Writables is an easy fix, I recommend always doing
so – it may not bring you a gain for every job, but if you’re low on
memory it can make a huge difference.
Tip 7) Use “Poor Man’s Profiling” to see what your tasks are doing
This is a trick I almost always use when first looking at the
performance of a MapReduce job. Profiling purists will disagree and say
that this won’t work, but you can’t argue with results!
In order to do what I call “poor man’s profiling”,
ssh into one of your slave nodes while some tasks from a slow job are running. Then simply run
sudo killall -QUIT java
5-10 times in a row, each a few seconds apart. Don’t worry — this
doesn’t cause anything to quit, despite the name. Then, use the
JobTracker interface to navigate to the
stdout logs for one of the tasks that’s running on this node, or look in
/var/log/hadoop/userlogs/ for a
stdout file of a task that is currently running. You’ll see stack trace output from each time you sent the
SIGQUIT signal to the JVM.
It takes a bit of experience to parse this output, but here’s the method I usually use:
- For each thread in the trace, quickly scan for the name of your Java
package (e.g. com.mycompany.mrjobs). If you don’t see any lines in the
trace that are part of your code, skip over this thread.
- When you find a stack trace that has some of your code in it, make a
quick mental note what it’s doing. For example, “something
NumberFormat-related” is all you need at this point. Don’t worry about
specific line numbers yet.
- Go down to the next dump you took a few seconds later in the logs. Perform the same process here and make a note.
- After you’ve gone through 4-5 of the traces, you might notice that
the same vague thing shows up in every one of them. If that thing is
something that you expect to be fast, you probably found your culprit.
If you take 10 traces, and 5 of them show
NumberFormat in
the dump, it means that you’re spending somewhere around 50% of your CPU
time formatting numbers, and you might consider doing something
differently.
Sure, this method isn’t as scientific as using a real profiler on
your tasks, but I’ve found that it’s a surefire way to notice any
glaring CPU bottlenecks very quickly and with no setup involved. It’s
also a technique that you’ll get better at with practice as you learn
what a normal dump looks like and when something jumps out as odd.
Here are a few performance mistakes I often find through this technique:
NumberFormat is slow – avoid it where possible.String.split, as well as encoding or decoding UTF8 are slower than you think – see above tips about using the appropriate Writables- Concatenating
Strings rather than using StringBuffer.append
These are just a few tips for improving MapReduce performance. If
you have your own tips and tricks for profiling and optimizing MapReduce
jobs, please leave a comment below! If you’d like to look at the code I
used for running the benchmarks, I’ve put it online at
http://github.com/toddlipcon/performance-blog-code/
Appendix: Benchmark Cluster Setup
Each node in the cluster is a dual quad-core Nehalem box with
hyperthreading enabled, 24G of RAM and 12x1TB disks. The TaskTrackers
are configured with 6 map and 6 reduce slots, slightly lower than we
normally recommend since we sometimes run multiple clusters at once on
these boxes for testing.