Compare Big Data Platforms vs SQL Server
Problem
SQL is derided by modern developers as 'Scarcely Qualifies as a Language'. But just how efficient are the new wave of NoSQL languages touted by bleeding-edge skunk works? This tip is a defense of SQL and of the relational model, and argues for the efficiency and suitability of relational technology. Check out this tip to learn more.Solution
SQL, or Structured Query Language, is one of the most versatile tools that an information analyst can use when working with relational databases. Initially developed around 40 years ago as an application of the mathematical theories of Codd, Boyce and others, it has since been embraced by the information technology industry and transformed into a range of dialects for a variety of platforms. With the core syntax and features reflected in easy-to-remember heuristics (SELECT, INSERT, UPDATE, DELETE), its popularity has soared and over the last twenty years, three vendors have come to the fore: Microsoft, with SQL Server; Oracle, with Oracle Database; and MySQL, developed by Sun and now also owned by Oracle.However, as astute readers of technology blogs may know, Big Data has come galloping onto the horizon. Arguably, the applications of Big Data originated (in recent times) with Google's MapReduce algorithms, and it has evolved with tremendous speed into a range of products: Node.js, Hadoop, MongoDB, RavenDB and more. Searching Google, one can find multitudes of articles expounding the benefits of Big Data. Marketers, long deprived of sexy sales slogans for 'boring' relational databases, have taken the term to heart, with the result that Big Data is now not only the 'next big thing' but is being touted as the only way forward in the shiny new 'Information Age'. Companies are being exhorted to use these new tools to leverage their existing data and expand their businesses in ways they have never been able to before.
Storage Format for Relational Databases vs. NoSQL
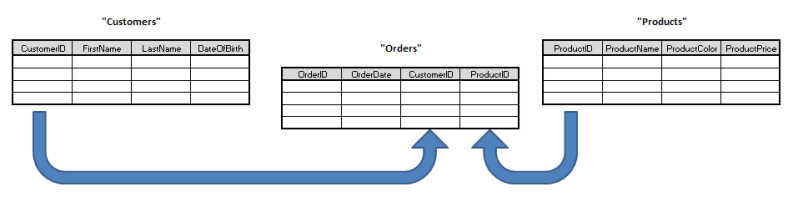
So, what's the difference between relational data and non-relational data - or SQL, and NoSQL (aka NewSQL)? Relational data is defined at the basic level by a series of table entities which contain columns and rows, linked to other table entities by shared attributes. So, for example, as the owner of a small online business you might have a MySQL database behind your website with a table recording the name and email address of your customers. Another table might record your product names and their prices. A third table might link the two, recording which customers bought which products, with additional information such as the date of purchase and whether or not any discount was applied.You can quickly see how this information could be useful; some analysis will give you the average spend per customer; a list of regular customers, and a list of inactive ones; a list of the most popular products. From this simple data you can make good business decisions: you can tempt back inactive customers with a targeted email campaign, you can adjust your stock to prioritize the most popular products. The possibilities are endless. At the core level, these queries against your data are performed in SQL, although various tools exist to hide this from the casual user.
Non-relational data, however, is not (by and large) stored in tables. Often called 'unstructured data', this data consists of separate records with attributes that vary, often per record. Say, for example, your small online business was a dating website recording, from a web page, the interests and ambitions of your members. Due to the huge variety of interests, you might wish to store each member as a document with the interests, and any attributes of those interests, laid out hierarchically. Relational databases are no good for this purpose - an 'Interests' table might list every conceivable interest, but recording an unknown number and combination of interests against each member forces the relational model to expand in ways it wasn't designed for. Standards such as XML and JSON, however, with variable nodes and node attributes, can be ideal since each record is stored uniquely with complex algorithms used for analysis and presentation.
Relational Data - Example Table Structure
NoSQL - Example Record in JSON

Data Variation
So Big Data is all very well when dealing with unstructured data. When caching common Google queries, or recording masses of highly-variable customer-centric information, the technologies that use it can perform well. But what about the majority of businesses? How often will their data structures change? After all, most online merchants will have customers, products, sales, suppliers, etc. In terms of the variation of the data - the measure of how the structure of data is subject to change over time - most merchants, through the very nature of business, will find they're working to a fairly static data model.After all, if you are a curtain manufacturer, your products will all have identical attributes - color, width, drop, price, fabric, style, thickness, etc. If you're a factory selling ball bearings, your ball bearings will have similar properties - diameter, density, material, price, quantity per batch, etc. These attributes are not likely to expand over time, and any expansion would take place within the data facts, rather than the data dimensions - say, for example, a new type of metal alloy was invented, this alloy would be added as a row in the materials table, rather than as a column in the products table.
So if we accept the argument that the rate of data variation is low amongst most businesses, then how important is the rise of Hadoop, Node.js, MongoDB/RavenDB and all the other NoSQL platforms? Is the rise of NoSQL simply the public perception of an inflated marketing bubble? We can argue that for OnLine Transaction Processing (OLTP) systems, which match the requirements for most businesses, NoSQL is not the right tool for the job.
Searching for Data
Let's now look at the algorithms for searching for data. Under a NoSQL data model, such as Hadoop, there exist a number of variations on a theme (and you can write your own) for searching for data using the MapReduce paradigm. This paradigm is that a typical analysis task, such as a series of read requests, is sent out to multiple nodes - servers - where the data resides. Each subset of the total request collects the data from the local data source, before a reduction algorithm aggregates and reduces the data to produce the desired result set. Some thought will show this approach works for certain types of unstructured data - for example, for string-searching unstructured tweets.However, for more structured data, this approach is flawed. Structured data tends to be held in central repositories rather than 'sharded' across multiple servers, and under a relational model searching for data is extremely efficient. For example, in Microsoft SQL Server the search algorithm can approach a pre-sorted table (a table using a clustered index based on a balanced-tree format) and search for particular values using this index, and/or additional indexes (think of them like overlays to the data) to locate and return the data. I'll skip the mathematics here, but many millions of records can hence be reduced to a b-tree search problem so that a single- or double-digit number of reads are required to return the desired data. In addition, partitioning can replicate some of the performance benefits of sharding, since sharding is horizontal partitioning except distributed across servers.
Reads and Writes
Carrying on with this theme, Big Data platforms such as Hadoop are acknowledged to be quicker at writes than relational databases. Why? Because in Hadoop, writes are 'thrown over the fence' asynchronously with no wait on the commit from the database engine. In relational systems, a write is an atomic, consistent, isolated, durable (ACID) transaction and only completes on commit - hence synchronous in it's very nature. This can cause unnecessary delays for applications that don't wish to wait for commit acknowledgement. Hadoop easily outperforms relational systems here, for the sheer asynchronism of the process.But what about reads? As argued above, reads take much longer, since the result set must be located (through mapping key-value pairs) then reduced across multiple nodes. Take a look at the JSON record in the image above - locating every unique product bought in interval X to Y would require a search on every customer record. If there are thousands of customers for a dozen products, this is extremely wasteful. Using a relational table, the query is broken down, optimized, filtered and returned much quicker. With relational systems, efficient structured reads (even on heaps, which tend to have sequential data stored on adjacent disk pages) can take place resulting in returns in the order of milliseconds, even for large result sets. Indeed, often the client application takes longer to render the result set than the server takes to supply it!
Total Cost of Ownership
'But it's FREE!', comes the wail from the IT manager. Is it? Apache Hadoop, to take an example, is indeed free at the point of use. The Apache Foundation have released Hadoop as open-source, so anyone can view the source code and see how it works. Anyone can download it. There's no core licensing fees. However, this doesn't mean it doesn't cost anything. The servers on which Hadoop must reside do indeed cost money. And as Big Data platforms are designed to scale out, rather than scale up, you'll need more and more servers to service your data requirements. Whereas production database systems servicing major businesses (and I can name a few) can sit on just a handful of relational database servers, Hadoop platforms are designed for large clusters of nodes and if you can't afford them - Hadoop may not be for you.'Just use commodity hardware!', is the next argument. Really - tie together hundreds of old PCs or battered low-rent servers in a crazy Beowulf-like cluster? Not only does this present major headaches when considering the long-term costs of storage, cooling, maintenance, this simply isn't viable for small- to mid-size businesses. The fact is that the TCO for a Big Data platform is simply too high, even when compared with Microsoft's frankly appalling licensing costs (for SQL Server). There is a third way - using an open-source relational platform, such as MySQL, but there are some missing features when compared against larger offerings and there's still the cost of support. However some notable names out there use MySQL - Facebook being the largest, and for certain applications this may be a suitable compromise.
Object-Relational Mapping
ORM, better known amongst DBAs and relational database developers as 'Object-Relational Mangling', is an umbrella term for a number of new tools that allow developers to call a connection to a database as an object, and interact with that object using pre-set methods. The ORM tool (such as nHibernate) will then translate the method call into a SQL query, which is sent to the database for processing. The result set is then returned to the entity that called the method. Since object-oriented programming does not play nicely with the relational model, there are inevitably some challenges when ORM tools generate SQL code. For example, nHibernate will generate large (sometimes, hundreds) of parameters to feed into a parameterized statement. This makes the resulting automatically generated statements hard to optimize, filling the plan cache (optimizer feature) in SQL Server with hundreds of ad-hoc plans, meaning increased delay in server response time thanks to increased I/O.On the flip side, modern developers normally use object-oriented methods to develop new tools, and calling a method on a connection object, passing in input parameters to return a result set, is natural and fits with the paradigm of method calls for the other 'black-box' features or libraries used in their languages. From the developer perspective, the ideal is to call a method with, for example, a customer number and return some attributes of that customer from the database into a result set. Under the relational-only model, they would need to either roll their own method that dynamically builds the query based on input parameters, or use in-line SQL queries, which is bad coding practice. Products such as nHibernate help bridge the gap by providing that level of translation to the relational layer.
Right Tool For The Job?
One consistent argument used by developers when attempting to win over the stubborn DBA with NoSQL tooling is that SQL and NoSQL are different toolsets to be used for different purposes. Confusing the two when trying to solve a problem that clearly belongs in the remit of just one platform is equivalent to using a screwdriver to hammer in a nail. But how true is this? Take server logs, for example. An extended log file for IIS 6.0 might contain one or more of the following fields: date, time, c-ip, cs-username, s-ip, s-port, cs-method, cs-uri-stem, cs-uri-query, sc-status, cs(User-Agent), etc. Although the fields are defined in a #comment at the beginning of the file, these fields are unlikely to change through the lifetime of the product. The data recorded is a mixture of date, time, IP address and character fields.Aggregating results from these logs is simple, and relational systems (with the right indexes) can do this with outstanding performance. In a NoSQL document store, each row is stored as a separate document inside a collection; to get, for example, the called URL from all records matching a particular IP, all documents will need to be scanned (string-searching on attribute), collated then reduced to the subset of data required. This approach is extremely inefficient, but analysis of server logs is frequently touted as a good application of NoSQL technology to real-world data mining.
There is an argument that issues such as the ORM/relational mismatch help provide the justification for a move to a non-relational platform. Various companies have tried it, and anecdotal evidence highlights various problems not just with the migration of data, but the ongoing benefits of it. For example, Foursquare's public apology following their catastrophic attempt to add a shard to their estate which resulted in an 11-hour outage; and the engaging account from Wireclub of the benefits (and pitfalls) of their migration from SQL Server to MongoDB should sound alarm bells with even the most pro-NoSQL DBA or developer - '...not only the database would crash and exit without providing any useful information but the data would also be left in a corrupted state.' (on MongoDB for Windows). However, the companies in both these examples determined NoSQL to be the data platform most suited to their future development as an organization, and they are learning to live with the features unavailable in more sophisticated relational platforms.
In Summary
Relational systems may have been born in the 1970s, but the feature set offered by the more advanced examples of relational platforms far outstrips the feature sets available in NoSQL implementations. Although NoSQL purports to be new, the concepts have been around for more than 20 years; look up 'network databases' and see the striking similarities to modern-day graph databases. The generation before us tried non-relational systems and the concepts simply didn't work - one can see the same story with new Agile and LEAN processes producing rafts of cheap code that's apt to break, versus the SSADM (Big Design Up Front) methodologies that gave us quality systems like our government defense and our banking infrastructure. NoSQL campaigners now say 'not only SQL' rather than 'no SQL' in belated realization that SQL actually has features to offer; these add-ons, such as Hive for Hadoop, provide a SQL-NoSQL translation layer. But the underlying document store, described by a colleague as a 'massive version of Notepad', is inefficient. This failure to build efficacious foundations of the new Information Age will be the undoing of our data-driven systems unless we tackle the structural problems at the heart of these new products, and rebuild them in an economical way.Next Steps
For further reading on structured and unstructured data storage technologies and expositions on the arguments above, please consult the following sources and read the extensive opinions available on the web:- Scaling Foursquare with MongoDB -> http://goo.gl/MzpWLb
- A Relational Model of Data for Large Shared Data Banks -> http://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf
- Don't Use MongoDB! -> http://pastebin.com/FD3xe6Jt
- Don't Use MongoDB - Rebuttal from 10Gen -> http://www.quora.com/MongoDB/How-much-credibility-does-the-post-Dont-use-MongoDB-have (Quora)
- Lessons Learned Migrating 2 Billion+ Documents at Craigslist -> http://www.10gen.com/presentations/lessons-learned-migrating-2-billion-documents-craigslist (Video)
No comments:
Post a Comment