Scheduling Workflows Using Oozie Coordinator
Introduction
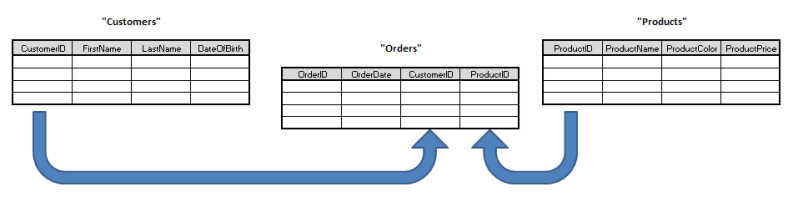
In Hadoop Ecosystem, most of the functionality like map-reduce jobs, pig scripts and hive queries are executed as batch jobs. This creates a lot of overhead in deployment and maintenance of hadoop components. As a solution to this, Oozie provides workflows in xml format using which we can define multiple Map/Reduce jobs into a logical unit of work, accomplishing the larger task [4]. This helps in chaining the related MapReduce jobs which can be either Hive queries or Pig scripts like mentioned in below diagram.

Workflows work perfectly when invoked on demand or manually. But for achieving higher level of automation and effectiveness, it becomes necessary to run them based on one or more of the following parameters: regular time intervals, data availability or external events. Then, we need more functionality than provided by Oozie workflows.
In this paper, Oozie Coordinator Jobs will be discussed which provide options to embed workflows and trigger them on regular time-intervals or on basis of data availability.
The Oozie coordinator allows expressing conditions to trigger execution of workflow in the form of the predicates [1]. These predicates are conditional statements on parameters like time, data and external events. If the predicate is satisfied, then only the workflow job/action is started.
The Oozie coordinator allows expressing conditions to trigger execution of workflow in the form of the predicates [1]. These predicates are conditional statements on parameters like time, data and external events. If the predicate is satisfied, then only the workflow job/action is started.
Oozie Coordinator System
As stated at Oozie documentation page [1], “Oozie is a Java Web-Application that runs in a Java servlet-container”. It uses XML for taking configuration inputs from user and uses a database (default is derby but MySQL, HSQLDB or any RDBMS database can also be used) to store:
- Definitions of Workflow and Coordinator
- Currently running workflow and Coordinator instances, including instance states, configuration variables and parameters.
Oozie Coordinator is a collection of predicates (conditional statements based on time-frequency and data availability) and actions (i.e. Hadoop Map/Reduce jobs, Hadoop file system, Hadoop Streaming, Pig, Java and Oozie sub-workflow). Actions are recurrent workflow jobs invoked each time predicate returns true.
Oozie version 2 and higher supports Coordinator Jobs. Coordinator Job is defined in the XML Process Definition Language.
Predicates are conditional statements, defined using attributes “interval, start-time and end-time” for time-based triggering and xml-tags “dataset and input-events” for data-availability based triggering of workflows.
Oozie version 2 and higher supports Coordinator Jobs. Coordinator Job is defined in the XML Process Definition Language.
Predicates are conditional statements, defined using attributes “interval, start-time and end-time” for time-based triggering and xml-tags “dataset and input-events” for data-availability based triggering of workflows.
Actions are the mechanism by which a workflow is triggered for the execution of a computation/processing task. Action contains description of one or more workflows to be executed.
Oozie is lightweight as it uses existing Hadoop Map/Reduce framework for executing all tasks in a workflow. This approach allows it to leverage existing Hadoop installation for providing scalability, reliability, parallelism, etc.
On the basis of functionality, Coordinator can be sub-divided into two major groups [2]:
1. Time-Based Coordinator: This type of Coordinator definition is used for invoking the workflow repeatedly after an interval between a specified period of time.
2.File-Based Coordinator: This type of Coordinator definition is used for invoking the workflow on the basis of data availability and data polling.
2.1 Simple File-Based Coordinator: The action is invoked whenever data available predicate is true.
2.2 Sliding Window-Based Coordinator: It is invoked frequently and data is aggregated over multiple overlapping previous instances. For example, invoking it at a frequency of 5 minutes and running action on aggregated previous 4 instances of 15 minutes data.
2.3Rollups-Based Coordinator: It is invoked after a long period of time and data is aggregated over multiple previous instances from last time of invocation. For example, it will run once a day, and will trigger a workflow that aggregates 24 instances of hourly data.
Oozie Coordinator Components and Variables
- Coordinator-App: It is a wrapper component that defines the attributes of a coordinator and includes all other components.
Attributes are:
- start , end : describes the start and end time in yyyy-mm-ddThh:mmZ format
- Time zone: describes the time zone (is the value of Z in the above time format) like UTC.
- Controls: It contains parameters like timeout, concurrency, etc. to configure the execution of coordinator job.
- Datasets: It contains the definition of multiple data sources and frequency of data polling.
Attributes are:
- Frequency: interval of time at which data polling is done.
- Initial-Instance: start time of data polling in yyyy-mm-ddThh:mmZ format.
- Uri-Template: URI of the data source. Expression language can be used. For example, ${YEAR} corresponds to current year. It helps in dynamic selection of data source directories.
- Done-flag: This flag denotes the success of data polling. It can be a file in which case the presence of file is checked before calling action. It can be left empty otherwise for implicit success message.
- Input-Events: denotes the processing of the input data before running the action.
- Data-in: it denotes the aggregated output data of input-event.
- Start-instance and end-instance: boundary of data instances that needs to be aggregated.
- Output-Events: denotes the processing of the output data after running the action.
- Data-out: it denotes the output dataset.
- Instance: instance of dataset that is to be used as sink for output.
- Action: It includes the path of the workflow that has to be invoked when predicate return true.
It could also be configured to record the events required to evaluate SLA compliance.
Oozie Coordinator Lifecycle Operations


The lifecycle operations of coordinator are similar to those of oozie workflow except start operation. “Start” is not applicable for coordinators.
- Submit/Run: Both operations submit the coordinator job to oozie. The job will be in PREP state till the mentioned start-time of the coordinator.
- Suspend: Suspends/pause the coordinator job.
- Resume: Resumes the execution of the coordinator job.
- Kill: kill the coordinator job and ends its execution.
- reRun: re-submitting the coordinator job/actions with new parameters.
Oozie Coordinator Example
In this section, we will see how to use oozie coordinator for scheduling and triggering of the workflows.
- A Sample Workflow: First of all, we need a oozie workflow job. For example purpose, I have taken the simple wordcount example provided by Apache-Hadoop-Distribution in hadoop-examples-0.20.2-cdh3u0.jar [6].
The workflow for wordcount is:
| <workflow-app xmlns='uri:oozie:workflow:0.1' name='java-main-wf'> <start to='mapreduce-wordcount-example' /> <action name='mapreduce-wordcount-example'> <java> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>default</value> </property> </configuration> <main-class>org.apache.hadoop.examples.ExampleDriver</main-class> <arg>wordcount</arg> <arg>${inputDir}</arg> <arg>${outputDir}</arg> </java> <ok to="end" /> <error to="fail" /> </action> <kill name="fail"> <message>Java failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> </kill> <end name='end' /> </workflow-app> |
Once workflow is created it has to be deployed correctly. A typical Oozie deployment is a HDFS directory, containing workflow.xml and a lib subdirectory, containing jar files of classes used by workflow actions.
For example, the directory structure in hadoop will be as shown below. (If user.name is training)
| [hadoop@localhost ~]$ hadoop dfs -ls /user/training/oozie/workflow/wordcount Found 2 items drwxr-xr-x - training supergroup 0 2012-09-18 12:05 /user/training/oozie/workflow/wordcount/lib -rw-r--r-- 1 training supergroup 918 2012-09-18 11:47 /user/training/oozie/workflow/wordcount/workflow.xml |
The job.properties file will have following properties:
| nameNode=hdfs://localhost:8020 jobTracker=localhost:8021 queueName=default inputDir=${nameNode}/data.in outputDir=${nameNode}/out user.name=training oozie.wf.application.path=${nameNode}/user/${user.name}/oozie/workflow/wordcount/ |
With job properties in place, this workflow can be invoked manually using the oozie workflows submit command from command-line.
| [training@localhost Desktop]$ oozie job -oozie=http://localhost:11000/oozie/ -config oozie/wordcount-demo/workflow/job.properties -run; |
job: 0000000-120918134457517-oozie-oozi-W
2. Oozie Coordinator Definition: As discussed above, coordinator-definitions will be different for different kind of triggering and scheduling.
So, we will take each kind of Coordinator one by one and schedule wordcount example on the basis of that.
Moreover, Oozie coordinators can be parameterized using variables like ${inputDir}, ${startTime}, etc. within the coordinator definition. When submitting a coordinator job, values for the parameters must be provided as input. As parameters are key-value pairs, they can be written in a job.properties file or a XML file. Parameters can also be provided in form of a java Map object if using JAVA API to invoke a coordinator job.
- Time-Based Coordinator
The generic definition for this kind of coordinator is
| <coordinator-app name="coordinator1" frequency="${frequency}" start="${startTime}" end="${endTime}" timezone="${timezone}" xmlns="uri:oozie:coordinator:0.1"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app> |
Save the file as coordinator.xml in a HDFS directory. (Please note that coordinator.xml is the only name which can be given to the file as oozie uses this default name for reading file in HDFS directory.)
| The coordinatorjob.properties can be defined as frequency=60 startTime=2012-08-31T20\:20Z endTime=2013-08-31T20\:20Z timezone=GMT+0530 workflowPath=${nameNode}/user/${user.name}/oozie/workflow/wordcount/ nameNode=hdfs://localhost:8020 jobTracker=localhost:8021 queueName=default inputDir=${nameNode}/data.in outputDir=${nameNode}/out |
oozie.coord.application.path=${nameNode}/user/${user.name}/coordOozie/coordinatorTimrBased
The coordinator application path must be specified in the file with the oozie.coord.application.path property. Specified path must be an HDFS path.
- File-Based Coordinator
| <coordinator-app name="coordinator1" frequency="${frequency}" start="${startTime}" end="${endTime}" timezone="UTC" xmlns="uri:oozie:coordinator:0.1"> <datasets> <dataset name="input1" frequency="${datasetfrequency}" initial-instance="${datasetinitialinstance}" timezone="${datasettimezone}"> <uri-template>${dataseturitemplate}/${YEAR}/${MONTH}/${DAY}/${HOUR}/ ${MINUTE}</uri-template> <done-flag> </done-flag> </dataset> </datasets> <input-events> <data-in name="coordInput1" dataset="input1"> <start-instance>${inputeventstartinstance}</start-instance> <end-instance>${inputeventendinstance}</end-instance> </data-in> </input-events> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app> |
Save the file as coordinator.xml in a HDFS directory. (Please note that coordinator.xml is the only name which can be given to the file as oozie uses this default name for reading file in HDFS directory.)
The coordinatorjob.properties can be defined as
| frequency=60 startTime=2012-08-21T15:25Z endTime=2012-08-22T15:25Z timezone=UTC datasetfrequency=15 datasetinitialinstance=2012-08-21T15:30Z datasettimezone=UTC dataseturitemplate=${namenode}/user/hadoop/oozie/coordinator/in inputeventstartinstance=${coord:current(0)} inputeventendinstance=${coord:current(0)} workflowPath=${nameNode}/user/${user.name}/oozie/workflow/wordcount/ nameNode=hdfs://localhost:8020 jobTracker=localhost:8021 queueName=default inputDir= ${coord:dataIn('coordInput1')} outputDir=${nameNode}/out oozie.coord.application.path=${nameNode}/user/${user.name}/coordOozie/coordinatorFileBased |
The coordinator application path must be specified in the file with the oozie.coord.application.path property. Specified path must be an HDFS path.
- Sliding-Window Based Coordinator
This is a specific usecase for the File-Based Coordinator where coordinator is invoked frequently and data is aggregated over multiple overlapping previous instances.
The rule for this can be generalized as
Coordinator-frequency < DataSet-Frequency
Coordinator-frequency < DataSet-Frequency
For example, the coordinator job.properties will be like
| frequency=5 … datasetfrequency=15 …… |
- Rollups Based Coordinator
This is a specific usecase for the File-Based Coordinator where coordinator is invoked after a long period of time and data is aggregated over multiple previous instances from last time of invocation.
The rule for this can be generalized as
Coordinator-frequency > DataSet-Frequency
The rule for this can be generalized as
Coordinator-frequency > DataSet-Frequency
| frequency=1440 …. datasetfrequency=60 ……. |
Running Coordinator Example from Command line
- Submitting/Running the coordinator job
$ oozie job -oozie http://localhost:11000/oozie -config coordinatorjob.properties [-submit][-run]
job: 0000672-120823182447665-oozie-hado-C
The parameters for the job must be provided in a file, either a Java Properties file (.properties) or a Hadoop XML Configuration file (.xml). This file must be specified with the -config option.
- Suspending the coordinator job
$ oozie job -oozie http://localhost:11000/oozie -suspend 0000673-120823182447665-oozie-hado-C
- Resuming a Coordinator Job
$ oozie job -oozie http://localhost:11000/oozie -resume 0000673-120823182447665-oozie-hado-C
- Killing a Coordinator Job
$ oozie job -oozie http://localhost:11000/oozie -kill 0000673-120823182447665-oozie-hado-C
- Rerunning a Coordinator Action or Multiple Actions
$ oozie job -rerun 0000673-120823182447665-oozie-hado-C [-nocleanup]
[-refresh][-action 1,3-5] [-date 2012-01-01T01:00Z::2012-05-31T23:59Z, 2012-11-10T01:00Z, 2012-12-31T22:00Z]
-action or -date is required to rerun. If neither -action nor -date is given, the exception will be thrown.
- Checking the Status of a Coordinator/Workflow job or a Coordinator Action
$ oozie job -oozie http://localhost:11000/oozie -info 0000673-20823182447665-oozie-hado-C
The info option can display information about a workflow job or coordinator job or coordinator action.
Invoking Coordinator Jobs from Java Client
The Oozie has exposed a JAVA API for invoking and controlling the workflows programmatically. Same API is also made applicable for coordinator but with some changes as coordinator and workflow differ in functioning.
//The service for executing coordinators on oozie public class CoordinatorOozieService { // Oozie Client OozieClient oozieClient = null; public CoordinatorOozieService(String url){ oozieClient = new OozieClient(url); } //To submit the coordinator job on oozie public String submitJob(String jobPropertyFilePath) throws OozieClientException, IOException{ // create an empty coordinator job configuration object //with just the USER_NAME set to the JVM user name Properties conf = oozieClient.createConfiguration(); conf.setProperty("user.name", "training"); //set the coordinator properties conf.load(new FileInputStream(jobPropertyFilePath)); // submit the coordinator job return oozieClient.submit(conf); } //To submit the coordinator job on oozie public String submitJob(Properties workflowProperties) throws OozieClientException, IOException{ // create an empty coordinator job configuration object //with just the USER_NAME set to the JVM user name Properties conf = oozieClient.createConfiguration(); //set the coordinator properties conf.putAll(workflowProperties); conf.setProperty("user.name", "training"); // submit the coordinator job return oozieClient.submit(conf); } // To run (submit and start) the coordinator job on oozie public String runJob(String jobPropertyFilePath) throws OozieClientException, IOException{ // create an empty coordinator job configuration object //with just the USER_NAME set to the JVM user name Properties conf = oozieClient.createConfiguration(); conf.setProperty("user.name", "training"); //set the coordinator properties conf.load(new FileInputStream(jobPropertyFilePath)); // submit and start the coordinator job return oozieClient.run(conf); } // To suspend the coordinator job on oozie public void suspendJob(String jobId) throws OozieClientException { // start the coordinator job oozieClient.suspend(jobId); } // To resume the coordinator job on oozie public void resumeJob(String jobId) throws OozieClientException { // start the coordinator job oozieClient.resume(jobId); } //To kill the coordinator job on oozie public void killJob(String jobId) throws OozieClientException { // start the coordinator job oozieClient.kill(jobId); } //To get the status of the Coordinator Job with id <jobID> public Status getJobStatus(String jobID) throws OozieClientException{ CoordinatorJob job = oozieClient.getCoordJobInfo(jobID); return job.getStatus(); } } |
Conclusion
The Oozie Coordinator can be used for efficient scheduling of the Hadoop-related workflows. It also helps in triggering the same on the basis of availability of the data or external events. Moreover, it provides lot of configurable and pluggable components which helps in easy and effective deployment and maintenance of the Oozie workflow jobs.
As the coordinator is specified in XML, it is easy to integrate it with the J2EE applications. Invoking of coordinator jobs through java has already been explained above.
As the coordinator is specified in XML, it is easy to integrate it with the J2EE applications. Invoking of coordinator jobs through java has already been explained above.
Enhancements
Oozie provides a new component, “Bundle” in its latest version 3. It provides a higher-level abstraction in which it creates a set of coordinator applications often called a Data Pipeline. Data Dependency can be inserted between multiple coordinator jobs to create an implicit data application pipeline. Oozie Lifecycle operations (start/stop/suspend/resume/rerun) can also be applied at the bundle level which results in a better and easy operational control.
References
[1] Oozie Yahoo! Workflow Engine for Hadoop: http://incubator.apache.org/oozie/docs/3.1.3-incubating/docs/
[2] Oozie Coord Use Cases: https://github.com/yahoo/oozie/wiki/Oozie-Coord-Use-Cases
[3] Better Workflow Management in CDH Using Oozie 2: https://github.com/yahoo/oozie/wiki/Oozie-Coord-Use-Cases
[2] Oozie Coord Use Cases: https://github.com/yahoo/oozie/wiki/Oozie-Coord-Use-Cases
[3] Better Workflow Management in CDH Using Oozie 2: https://github.com/yahoo/oozie/wiki/Oozie-Coord-Use-Cases
[5] Apache Hadoop: http://hadoop.apache.org/
[6] Index of public/org/apache/hadoop/hadoop-examples/0.20.2-cdh3u0:
https://repository.cloudera.com/artifactory/public/org/apache/hadoop/hadoop-examples/0.20.2-cdh3u0/
[6] Index of public/org/apache/hadoop/hadoop-examples/0.20.2-cdh3u0:
https://repository.cloudera.com/artifactory/public/org/apache/hadoop/hadoop-examples/0.20.2-cdh3u0/